[LeetCode] 更快的 Recursion?! 用 Divide-and-Conquer 解 #10 Regular Expression Matching
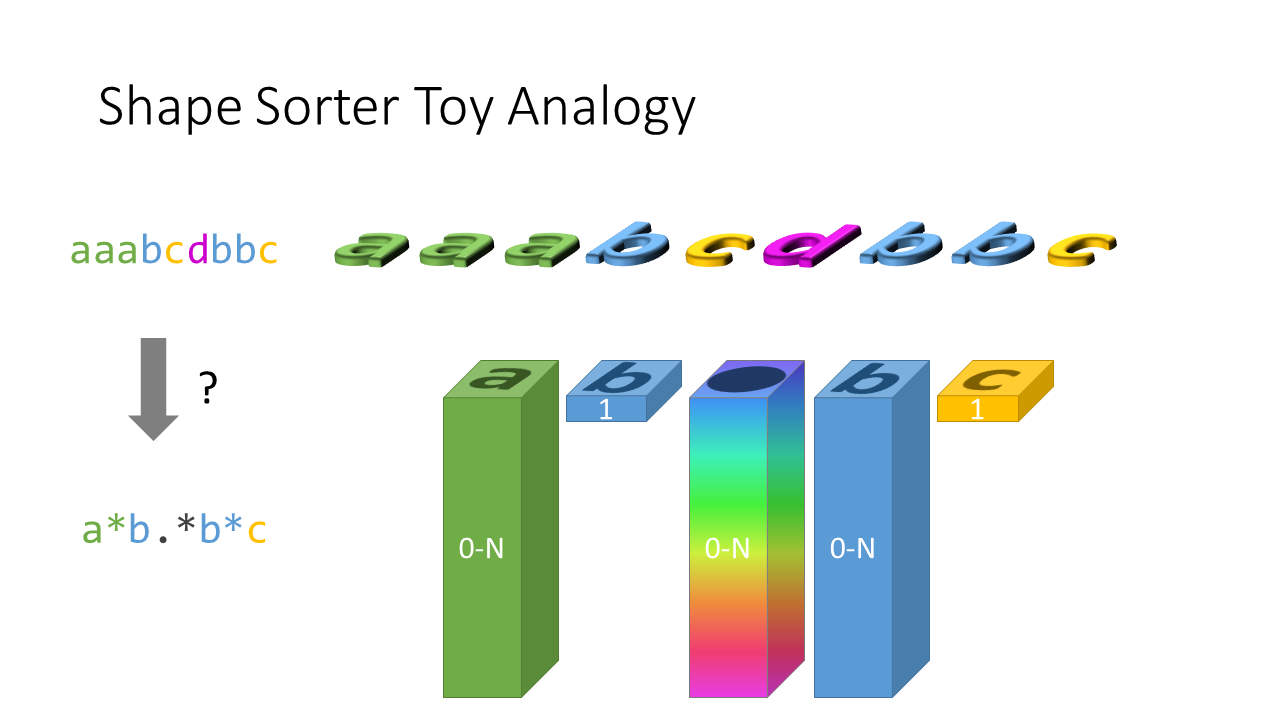
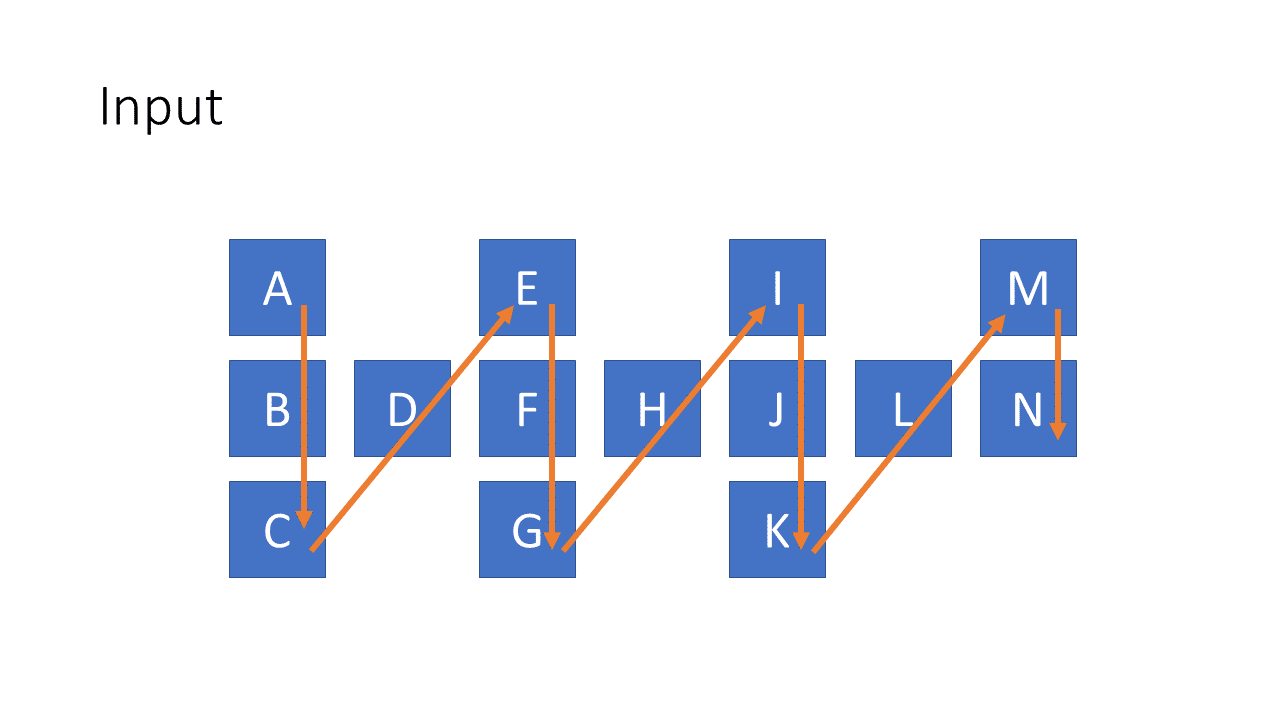
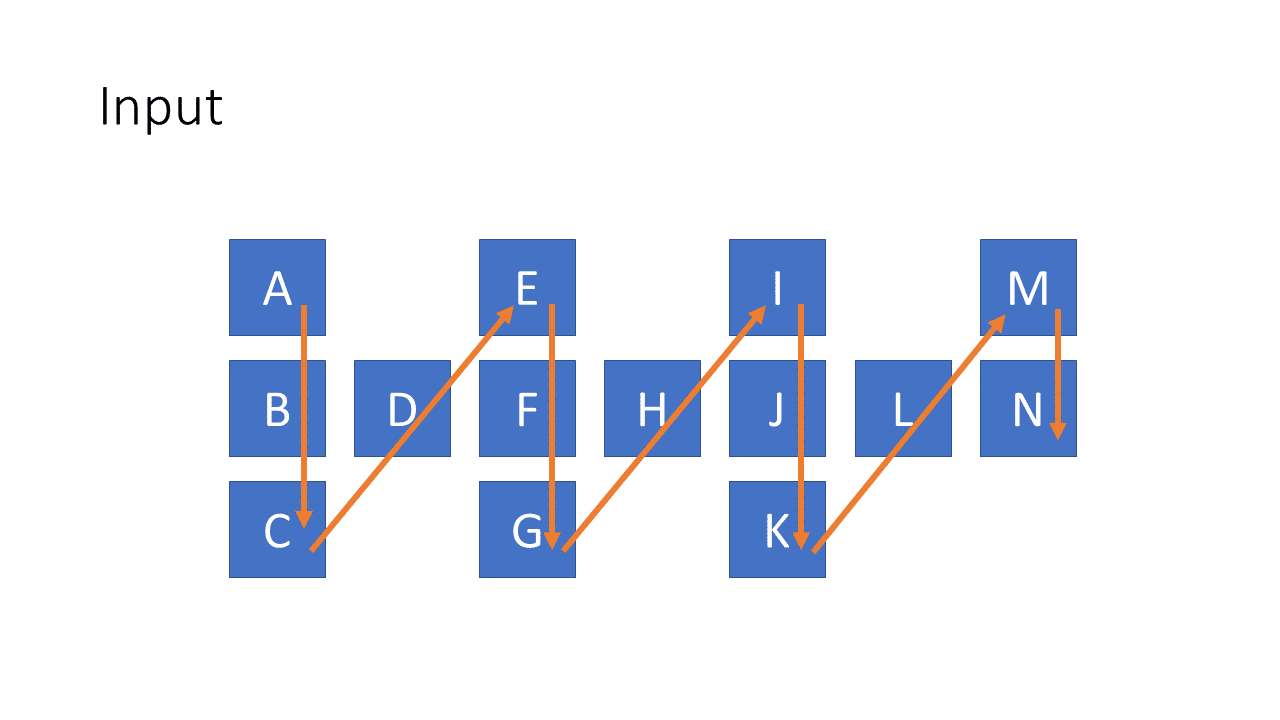
這題幾乎所有解答不是用從左往右的 Recursion 來解就是 DP 解。但我這次要用從中間開始的 Recursion 來追上 DP 的速度。 直覺的比喻 寶寶最愛玩的形狀配對盒今天要來幫助我們解題了! 為什麼我會想到用這個比喻就是之前看了一個 Reddit " Devs watching QA test the product " 一個幽默影片裡面就惡搞寶寶最愛玩的形狀配對盒子,把所有積木都丟到正方形孔去。 假設今天我們要把 " aaabcdbbc " 這串 s 測試能不能 match 一段 regular expression " a*b.*b*c "。 有 " * " 符號的我們就用一個什麼都裝的下的積木盒來代表、沒有 " * " 符號的我們用只能裝下 1 個積木的積木盒代表: 所以題目問的就是: 我們可以從左往右依序丟積木,符合積木盒上的數目要求嗎? 這樣丟就可以了: 什麼時候會失敗? 你沒丟完的時候,別想把積木藏起來: 或是有積木盒沒丟到數目要求: 但不是每一個積木盒都要丟," x* " 類型的積木盒你不丟也無所謂: 為何不能遇到 * 就狂丟 LeetCode 第一個解答是從左往右丟積木,遇到 " x* " 的積木盒,要嘛就是丟一個要嘛就是不丟,因為後面會發生什麼事還不知道,都試試看再說。 為什麼我們遇到 " x* " 會沒辦法決定要不要丟? 舉個例子像是 s = "aaa", p = "a*a" ,如果你把 3 個 " a " 都丟到 p[0:1] 的 " a* " 那最後面的 " a " 要誰來 match? 這時候 greedy 反而會失敗,所以你只能試所有的可能性。 各個擊破 (Divide and Conquer) 有點像 Quicksort,我們先取中間的 character 找到適合的積木盒丟下去: 不過要記得每個可能性都還是要試過。要從左往右或隨機挑就隨便你了。 接著我們問說左邊剩下的 input string 可以被 match 嗎? 再問右邊可以被 match 嗎? 就這樣 ...