[工作效率][Linux] 指令完成寄信通知
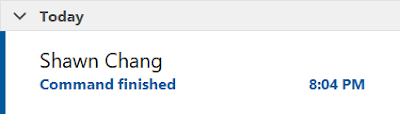
有些再簡單不過的指令像是 mv, cp, rm 遇到檔案一多的時候有時候可以跑好幾分鐘,甚至一小時以上。我也不曉得他什麼時候會跑完,30 秒? 10 分鐘? 2小時? 都有可能。 手邊也暫時沒其他工作可以平行進行的話,也只能放著讓他跑。 但時不時就會好奇他跑完了沒,一直來回切換視窗,或是去忙別的事卻一直跑回房間看螢幕。這時候我們就會很想要讓他跑完時通知我們。 Sequential Commands 最簡單的方法就是與其執行一個指令,不如執行 multiple commands,讓前面指令跑完就跑通知用的指令,我們這邊以 sleep 當作一個跑很久的指令: sleep 10; notify_me 要注意的是這裡最好用 ; 把指令串起來,最好不要用 &&,因為 && 一定要前面的指令成功 (return zero exit code),後面的指令才會執行,我們最好別太把握前面的指令跑到一半一定會不會發生錯誤。 通知的媒介 至於通知的指令要用哪種方式,我就有試過以下的方式: 播放聲音通知 在 VNC 視窗傳送通知到 VNC 桌面 (e.g., notify-send) 用第三方工具傳送通知 (e.g., Slack, Teams) 寄送 email 通知 但實際用過之後才發現一些缺點。聲音很容易因為人不在房間就沒聽到;VNC 視窗傳送就限制你只能在 VNC 視窗跑指令,而且人沒盯著螢幕也很容易錯過;第三方工具看起來最棒,但有時因為第三方工具或網路不穩就是會沒送到通知。 寄信+手機 app 還是最可靠 最可靠的還是透過簡單的指令像是 mail, sendmail, mutt 等工具來寄信。不過 IT 要先設定好信箱,但公司通常都會有。 於是我們就可以在 .bashrc 寫一個 function,例如我們可以使用 mutt 來當作寄信的工具: # Send an email with only the subject # # Examples: # mail2me # mail2me "Command finished" function mail2me() { local -r subject="$1" mutt -s "${subject}" ...